Scaling Sameness
The hidden fragility of AI monocultures and why redundancy requires diversity.
There is an intuitive logic to redundancy. Send three engineers to check the bridge. Have two pilots in the cockpit. Run the numbers twice. If independent reviewers reach the same conclusion, we treat that agreement as evidence the conclusion is sound. Having a second (or more) pair of eyes on a process, a deliverable, a product helps reduce the risk of an individual’s blind spot undermining the desired result.
Now apply that logic to AI agents. Organisations deploying multi-agent systems — networks of AI agents collaborating on all sorts of tasks — often rely on a similar intuition. More agents, more perspectives, more robustness. If several agents converge on the same answer, that convergence must mean something.
But what if it doesn't?
In our recent report analysing multi-agent risks, we identified six failure modes unique to systems where multiple AI agents interact. One turns the presumed resilience of redundancy on its head: monoculture collapse.
The problem with shared DNA
When multiple agents in a system are built on the same foundation model, or on models trained with similar data, architectures, and techniques, they tend to share capabilities as well as blind spots, biases, failure patterns, ways of reasoning. This means that systems notionally built on different AI models can still form a monoculture. A flaw that exists in every agent isn't caught by adding more agents, it becomes a structural property of the system.
In a genuinely diverse group, one member's weakness is another's strength. That diversity is what makes redundancy valuable. But in an AI monoculture, the “independent” reviewers aren't truly independent at all. They share the same training heritage, the same statistical tendencies, the same gaps in reasoning. When they agree, it may simply mean they're all wrong in the same way.
This matters most in the settings where multi-agent collaboration is supposed to shine: collaborative swarms, ensemble verification systems, multi-agent deliberation frameworks. These architectures are built on the appealing assumption that spreading a task across many agents yields robustness. In these settings, diversity is important for both safety & reliability (correlated errors), but also to achieve the desired performance benefits (such as producing creative solutions). Independence is also crucial in a guardrail typically implemented in many agentic and non-agentic systems in production: using an LLM as judge (more on this below).
Why such failure is hard to spot
In a monoculture, systemic failure presents as successful corroboration.
A single adversarial prompt, an unusual edge case, a novel scenario outside the training distribution can trigger correlated failures across all agents simultaneously. What makes this dangerous is that correlated failure can be indistinguishable from genuine agreement: every agent reaches the same conclusion, with high confidence, and none of them flag a problem.
To a human operator or to a governance layer monitoring agent outputs this looks like the system working exactly as intended. Multiple agents checked the work, they all agreed, and everything appears robust.
But the agreement is an artefact of shared vulnerability rather than correctness. The system has collapsed uniformly, and nothing in the architecture is designed to detect it. For any oversight layer trying to catch errors, this is a secret yet serious problem: the very signal meant to indicate reliability (different parties support a statement or finding) is the one most easily produced by correlated failure.
The evidence is catching up
When we published our report in mid-2025, agentic monoculture collapse was largely a theoretical concern grounded in the broader literature on algorithmic monocultures. Since then, empirical evidence has started to confirm the pattern.
A study examining over 350 LLMs found that model errors are highly correlated, with models agreeing roughly 60% of the time when both make mistakes on the same benchmark. More troublingly, the correlation is strongest among the largest and most accurate models, which are the ones most likely to be deployed in high-stakes, multi-agent systems. Distinct architectures and different providers are not enough to break the pattern.
This has direct implications for another increasingly common practice: using LLMs to evaluate other LLMs. When the judge shares the same biases and failure modes as the model it's assessing, systematic errors can go undetected or worse, get reinforced. A model may rate its own style of reasoning more favourably, a tendency known as self-preference bias.
What this means for governance
If you're a regulator, policymaker, or senior leader overseeing AI deployments, monoculture collapse raises a specific and practical question: can you trust your multi-agent system's corroborations?
A few implications are worth drawing out.
Redundant isn't resilient. Running the same query through multiple instances of the same model (or closely related models) doesn’t provide the independent verification it appears to. System-level risk assessments need to account for model provenance and the degree of true diversity in the agent pool.
Verification metrics can mislead. If your governance framework treats agent agreement as a signal of reliability, monoculture collapse can systematically deceive it. Monitoring frameworks should look for patterns of agreement, especially unanimous agreement in ambiguous or novel situations, as a potential red flag.
Evaluation needs methodological independence. Evaluation pipelines should incorporate genuinely different methods where feasible: human review, rule-based checks, LLM-based-judges with meaningfully different training lineages.
Diversity is a design challenge. Achieving meaningful diversity in a multi-agent system takes deliberate architectural decisions: varying foundation models, training approaches, prompting strategies, and reasoning frameworks. This is a developing practice, and may fundamentally require accepting trade-offs in single-agent consistency or efficiency.
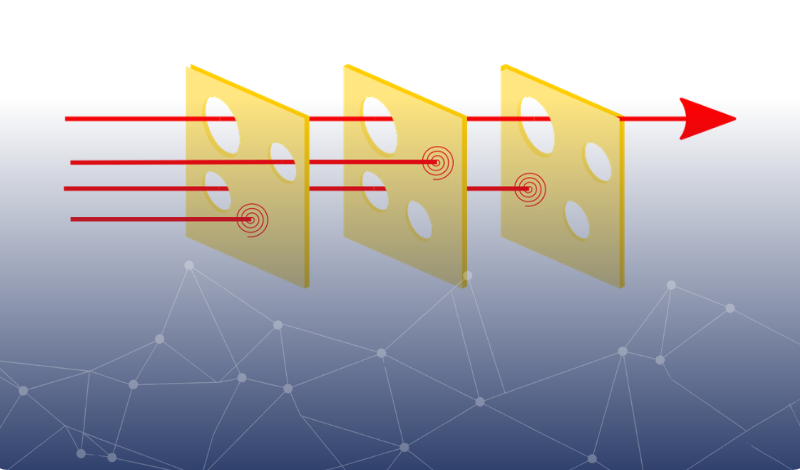
The Swiss cheese model is a brilliant mental model to think about risks and defences: "The risk of a threat becoming a reality is mitigated by the different types of defenses which are ‘layered’ behind each other.” The problem with using AI systems as layers of control is that the slices, while each still tastes good, can all start to look the same, with their holes aligned and harms passing through multiple layers with ease.
Looking ahead
Our work was cited by the International AI Safety Report, a signal that the risks of multi-agent systems are entering global policy discussion. That's encouraging. Awareness is necessary and the harder, more consequential work follows: building the governance frameworks, testing regimes, and system architectures that can detect and mitigate failure modes like monoculture collapse before they cause harm.
Trusting endorsement by different parties’ comes almost instinctive. It serves us well in many contexts. But when the agents that corroborate information among each other are, in a meaningful sense, the same agent wearing different labels, their verifications tell us less than we think. Recognising the distinction between accurate endorsement and correlated failure may be one of the most important conceptual shifts for anyone governing AI systems at scale.
Clarity, in this case, means treating agent corroboration as something to be tested rather than trusted.
This post draws on Risk Analysis Techniques for Governed LLM-based Multi-Agent Systems, a report by Gradient Institute.
Image credits: Wikipedia
About the authors

Alberto Chierici
Alberto is an AI specialist at Gradient Institute. He has a PhD in Computer Science from New York University, where he researched AI dialogue systems and how people interact with them. Alberto built different ventures and machine learning products at scale. He loves reading about philosophy and writing about AI and society.

Alistair Reid
Alistair (PhD, University of Sydney) leads research engineering at Gradient Institute, working at the intersection of AI safety, policy, and practice. His work spans technical research on topics including multi-agent systems and evaluation validity, policy advisory for government and industry, and translating research into practical guidance, including national guidelines on AI ethics and lead authorship of Gradient Institute's report on risk analysis for multi-agent deployments.

Simon O'Callaghan
Simon heads technical AI governance at Gradient Institute. He has over 15 years' experience applying machine learning across a range of domains, and has led assessments of high-risk AI systems in the banking, insurance, human resources, and public sectors. He is also a major contributor to the AI Governance guidance developed with Australia's National AI Centre, which serves as the primary AI governance reference for Australian businesses.